Multimodal Memory Puzzles
ATM-Bench
According to Me: Long-Term Personalized Referential Memory QA
Multimodal, multi-source personal memory question
answering over long time horizons
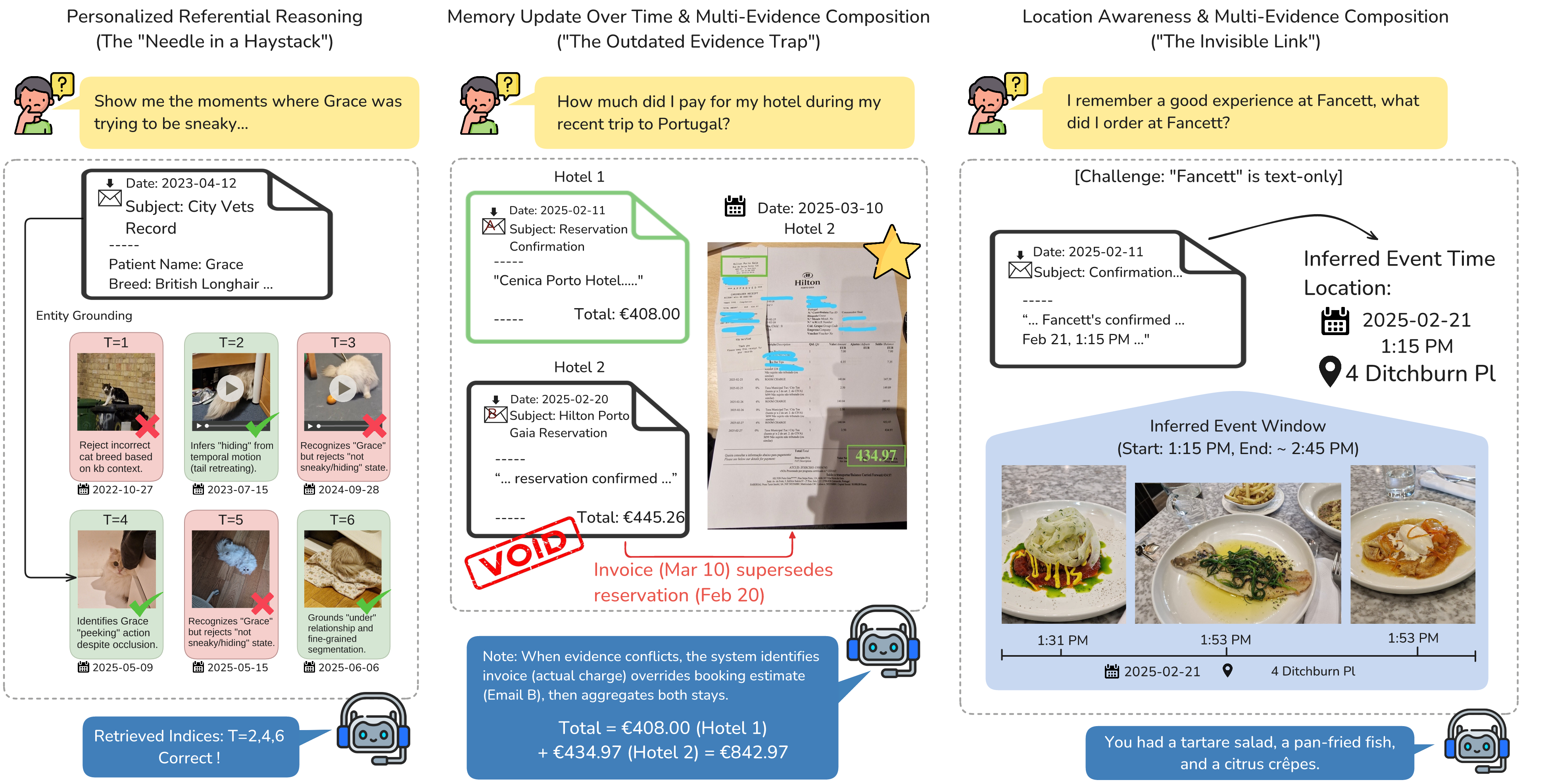
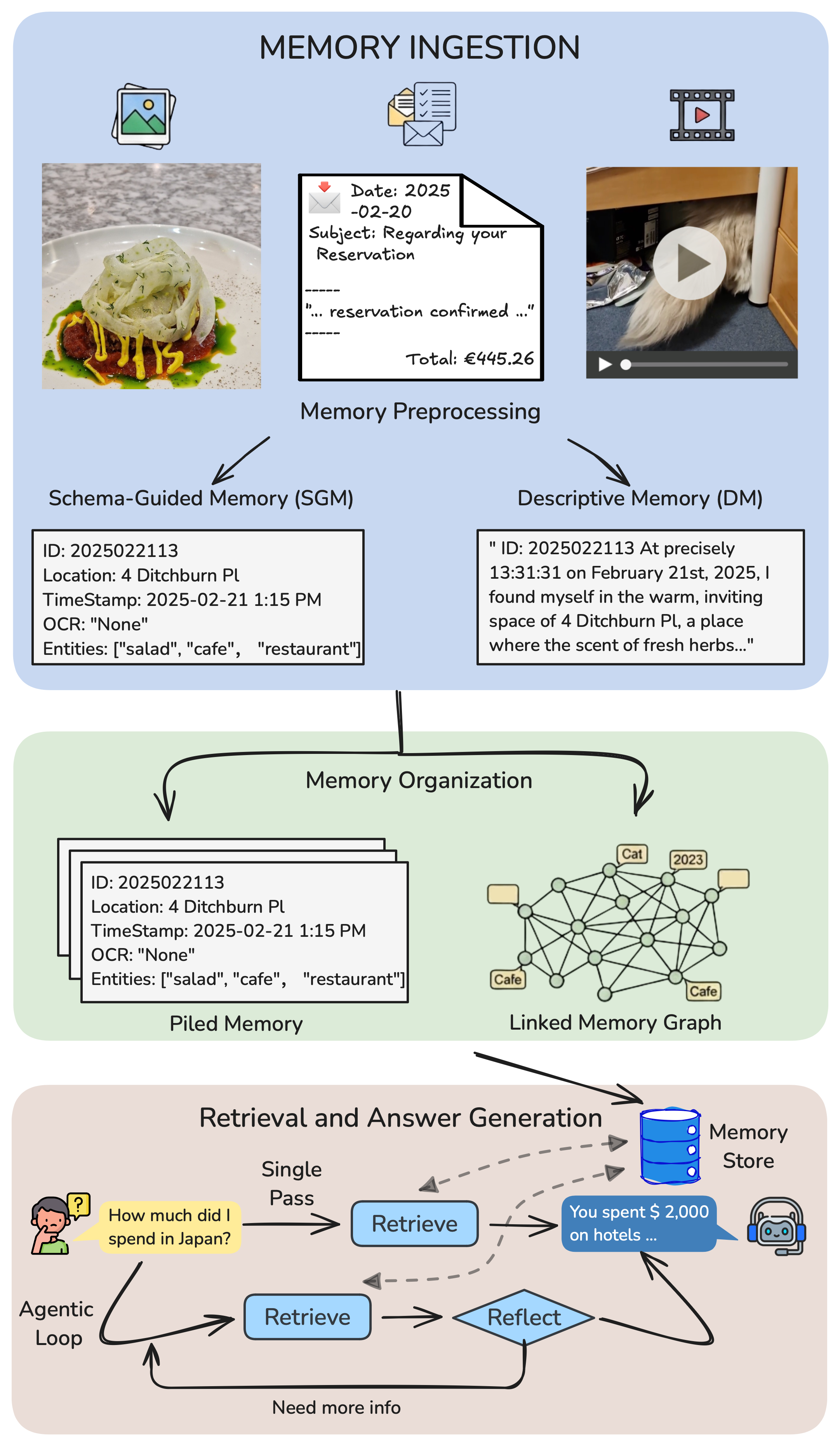
ATM-Bench is built for the kind of memory questions that sound casual to humans but break systems in
practice: outdated receipts, weak location clues, ambiguous references, and moments where the right
answer is to abstain.
Jingbiao Mei,
Jinghong Chen,
Guangyu Yang,
Xinyu Hou,
Margaret Li,
Bill Byrne
University of Cambridge
~4 years
personal memory horizon
Long-range references across years, not short chat windows.
3 sources
images + videos + emails
The answer often lives across multiple modalities at once.
2.25M
token context
A realistic haystack for retrieval, grounding, and reasoning.
~30%
multi-evidence questions
Single-pass lookup is often not enough to answer correctly.
<20%
accuracy on Hard
The hardest split still exposes large gaps in current systems.