According to Me: Long-Term Personalized Referential Memory QA
Multimodal, multi-source personal memory question
answering over long time horizons
ATM-Bench is built for the kind of memory questions that sound casual to humans but break systems in
practice: outdated receipts, weak location clues, ambiguous references, and moments where the right
answer is to abstain.
Jingbiao Mei,
Jinghong Chen,
Guangyu Yang,
Xinyu Hou,
Margaret Li,
Bill Byrne
~4 yearspersonal memory horizonLong-range references across years, not short chat windows.3 sourcesimages + videos + emailsThe answer often lives across multiple modalities at once.2.25Mtoken contextA realistic haystack for retrieval, grounding, and reasoning.~30%multi-evidence questionsSingle-pass lookup is often not enough to answer correctly.<20%accuracy on HardThe hardest split still exposes large gaps in current systems.
ATM-Bench demo: multimodal personal memory QA in action.
Personalized assistants should remember lived experience, not just chat logs. ATM-Bench targets the harder
regime: multimodal, multi-source personal memory QA grounded in real evidence from images, videos, and emails.
The challenge is not merely finding one matching memory item. It is deciding which pieces still hold, which ones
conflict, and when the evidence is not strong enough to answer at all.
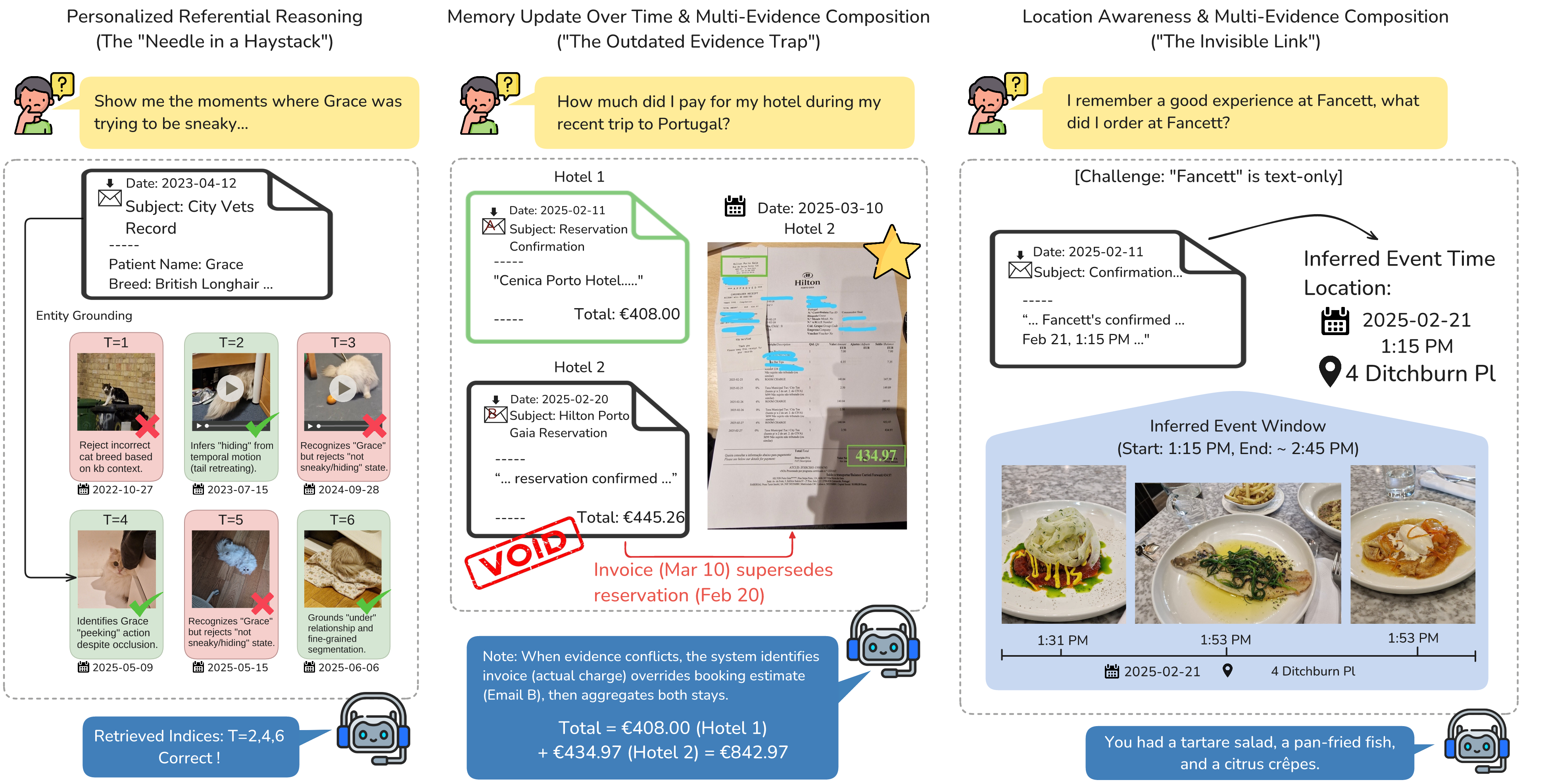
The benchmark teaser figure. The cards below unpack these cases into clearer, demo-friendly stories.
Four Memory Puzzles
These are the kinds of examples that make ATM-Bench memorable. Each one looks natural at the surface and then
turns into a retrieval, grounding, and reasoning trap.
Case 01
Personal Reference Resolution
"Show me the moments where Grace was trying to be sneaky."
imagesvideosentity grounding
Why it is tricky. The assistant must resolve who "Grace" is, reject visually similar but
wrong moments, and distinguish "trying to hide" from merely appearing in frame.
What weak systems do. They anchor on the wrong pet attributes or retrieve frames that look
close but do not support the sneaky state.
Correct behavior. Ground the entity first, then retrieve only the evidence that truly
supports the hidden or peeking action.
Case 02
Conflicting Evidence Over Time
"How much did I pay for my hotel during my recent trip to Portugal?"
emailsreceiptstemporal update
Why it is tricky. A reservation email and a later invoice disagree, and the final answer
requires composing evidence across two stays.
Typical model mistake. Trust the earlier booking estimate, ignore the superseding invoice,
and miss the conflicting-evidence update.
Correct behavior. Prefer the final invoice over stale booking evidence, then aggregate both
hotels to reach the grounded total of EUR 842.97.
Case 03
The Invisible Link
"I remember a good experience at Fancett. What did I order at Fancett?"
emailsphotoslocation inference
Why it is tricky. "Fancett" appears in text-only confirmation evidence, while the dishes
appear only in photos. The system has to infer the event window, venue, and then connect the right images.
Failure mode. Retrieve nearby meal photos from the same day without grounding them to the
correct place and time.
Correct behavior. Infer the restaurant visit from the confirmation, narrow the time window,
and only then read the dishes from the linked visual evidence.
Case 04
When the Right Answer Is "I Don't Know"
"Which wine did I order at Fancett that night?"
abstentionevidence sufficiencyhallucination control
Why it is tricky. The assistant may recover the restaurant and the meal, yet still lack any
grounded evidence about the drink order.
What weak systems do. Fill the gap with a plausible but unsupported guess once some nearby
memories have been found.
Correct behavior. Return an abstention because the retrieved memories support the dishes,
not the wine.
What ATM-Bench Measures
The benchmark is not just larger. It is structured around failure modes that matter for real personal-memory
assistants: weak references, stale evidence, cross-source composition, and calibrated abstention.
PR
Personalized references
Resolve names, nicknames, and indirect descriptions against personal multimodal memories.
LA
Location awareness
Infer where an event happened even when the place appears only in sparse, indirect evidence.
MUT
Memory updates over time
Prefer later and more authoritative evidence when bookings, plans, and outcomes conflict.
ME
Multi-evidence composition
Compose several partial clues before answering, instead of trusting the first matching item.
ABS
Abstention
Decline to answer when the evidence is insufficient, even if a plausible guess is tempting.
Compare ATM-Bench against prior memory benchmarks
Aspect
Prior Benchmarks
ATM-Bench
Memory modality and source
Mostly dialogue-only or single-modality settings
Images + videos + emails in one benchmark
Data origin
Primarily synthetic or hybrid data
Human-curated personal memory QA with evidence labels
Lower multi-evidence proportion in common settings
~30% of questions require multi-evidence composition
Methods
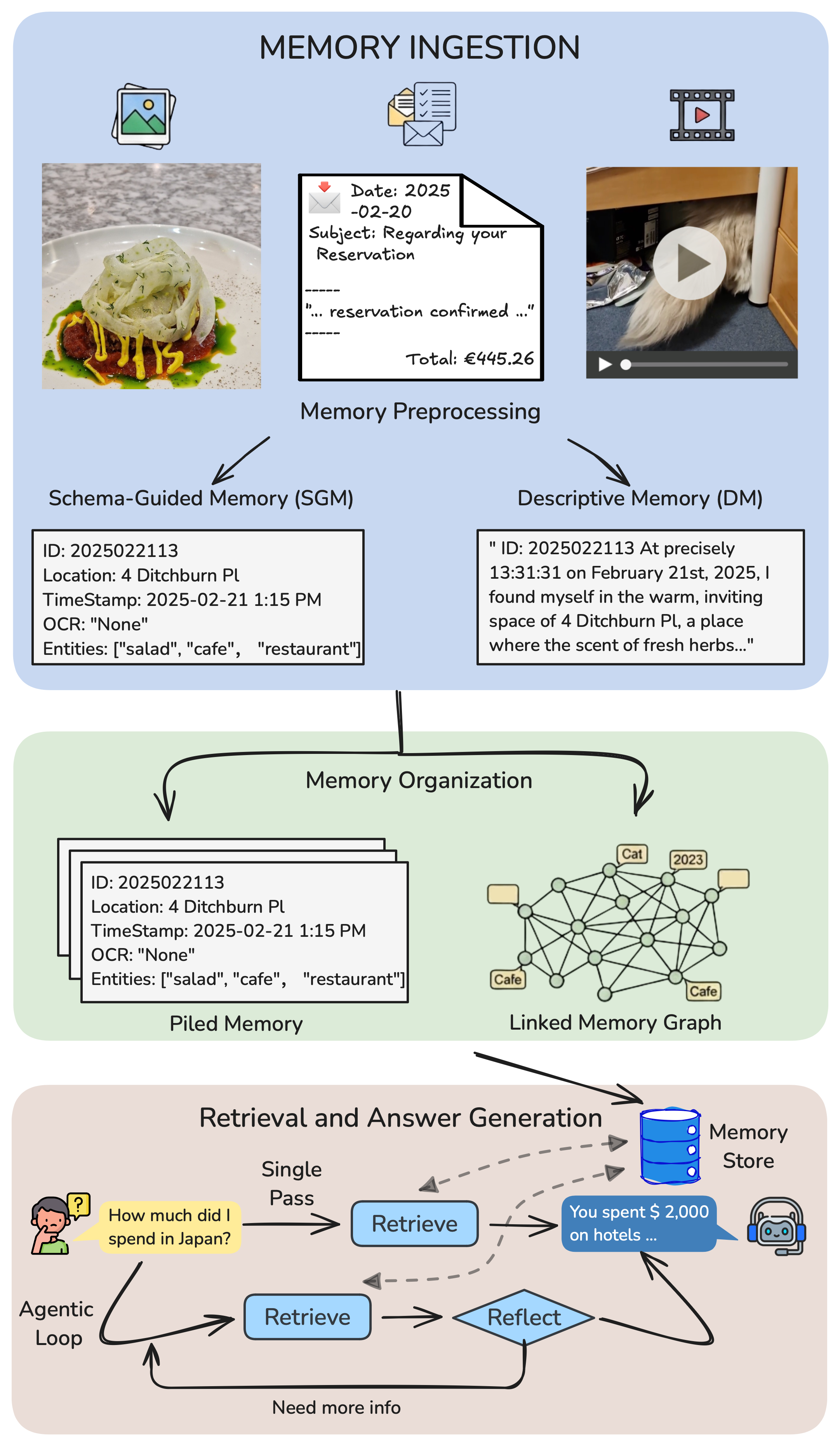
ATM models the assistant as a staged memory pipeline: ingest multimodal artifacts, organize them into memory
structures, retrieve evidence under budget, and only answer when the supporting memories are grounded.
ATM method: memory ingestion, organization, retrieval, and answer generation.
Citation
If you use ATM-Bench in your research, please cite:
@article{mei2026atm,
title={According to Me: Long-Term Personalized Referential Memory QA},
author={Mei, Jingbiao and Chen, Jinghong and Yang, Guangyu and Hou, Xinyu and Li, Margaret and Byrne, Bill},
journal={arXiv preprint arXiv:2603.01990},
year={2026},
url={https://arxiv.org/abs/2603.01990},
doi={10.48550/arXiv.2603.01990}
}